We have a new preprint which follows up on our earlier work presented at the IROS Human Multi-Robot workshop a few months ago.
This is the result of an ongoing collaboration with an undergraduate research intern that I worked with over the summer, Xijia Zhang, and is one of my favorite papers this year. We started with a simple question: can we use large language models (LLMs) to generate faithful and plausible natural language explanations for an arbitrary agent policy model (e.g. deep neural network)? Prior works either require large, annotated datasets in order to produce explanations (which is impractical when explaining arbitrary agent behavior), or use pre-defined language templates which limits explanation expressivity. LLMs offer a potential solution given their effective few-shot reasoning ability, however, they are also prone to hallucination which results in inaccurate explanations. This is particularly dangerous as humans are often unable to identify LLM hallucinations (we show this in our preprint), which means people may make assumptions about agent behavior that is not true.
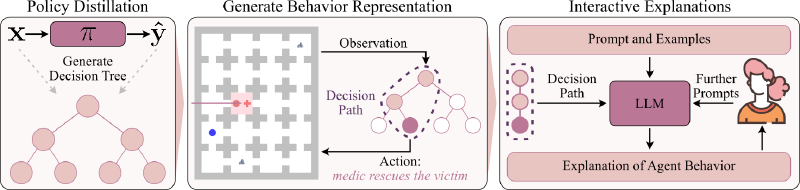
In this work, we propose an LLM-friendly representation for an agent’s behavior that is easy for an LLM to reason with, thus reducing hallucination. This representation is obtained by distilling an agent’s behavior into a decision tree and translating the ordered set of decision rules associated with specific paths into a textual prompt. There are four main take-aways from this work:
- Users prefer explanations generated by our method over baseline approaches, and on-par with those created by human domain experts.
- Our approach significantly reduces LLM hallucinations compared to other representational methods.
- The LLM can effectively reason over agent behavior, allowing it to predict an agent’s intent and future actions. We conjecture that this reasoning ability is what makes the explanations so effective.
- Our approach enables interactivity, in which a user can query the LLM with follow-up questions, e.g. counterfactuals.
Understanding Your Agent: Leveraging Large Language Models for Behavior Explanation
Xijia Zhang, Yue Guo, Simon Stepputtis, Katia Sycara, Joseph Campbell
Abstract: Intelligent agents such as robots are increasingly deployed in real-world, safety-critical settings. It is vital that these agents are able to explain the reasoning behind their decisions to human counterparts; however, their behavior is often produced by uninterpretable models such as deep neural networks. We propose an approach to generate natural language explanations for an agent’s behavior based only on observations of states and actions, thus making our method independent from the underlying model’s representation. For such models, we first learn a behavior representation and subsequently use it to produce plausible explanations with minimal hallucination while affording user interaction with a pre-trained large language model. We evaluate our method in a multi-agent search-and-rescue environment and demonstrate the effectiveness of our explanations for agents executing various behaviors. Through user studies and empirical experiments, we show that our approach generates explanations as helpful as those produced by a human domain expert while enabling beneficial interactions such as clarification and counterfactual queries.